Build Log
Two Weeks In, Rearchitecture
After two weeks of building, I paused. I noticed I was writing code to reshape data into other shapes of data. I had debug files and intermediate files everywhere.
I decided I had two fundamental artifacts: transcript and diarization. I can derive everything else at query time.
I'm still figuring out what's straight noise vs. what's incorrect but worth keeping in my source of truth artifacts. Whisper sometimes hallucinates "empty" segments where start time equals end time. I don't need those. But hallucinated words where there should be silence — I'm still wondering how to catch those without side effects. Do I remove them completely? Flag them and keep them? I built a validation tool that helped me understand the model's outputs. These are the questions I'm sitting with now.
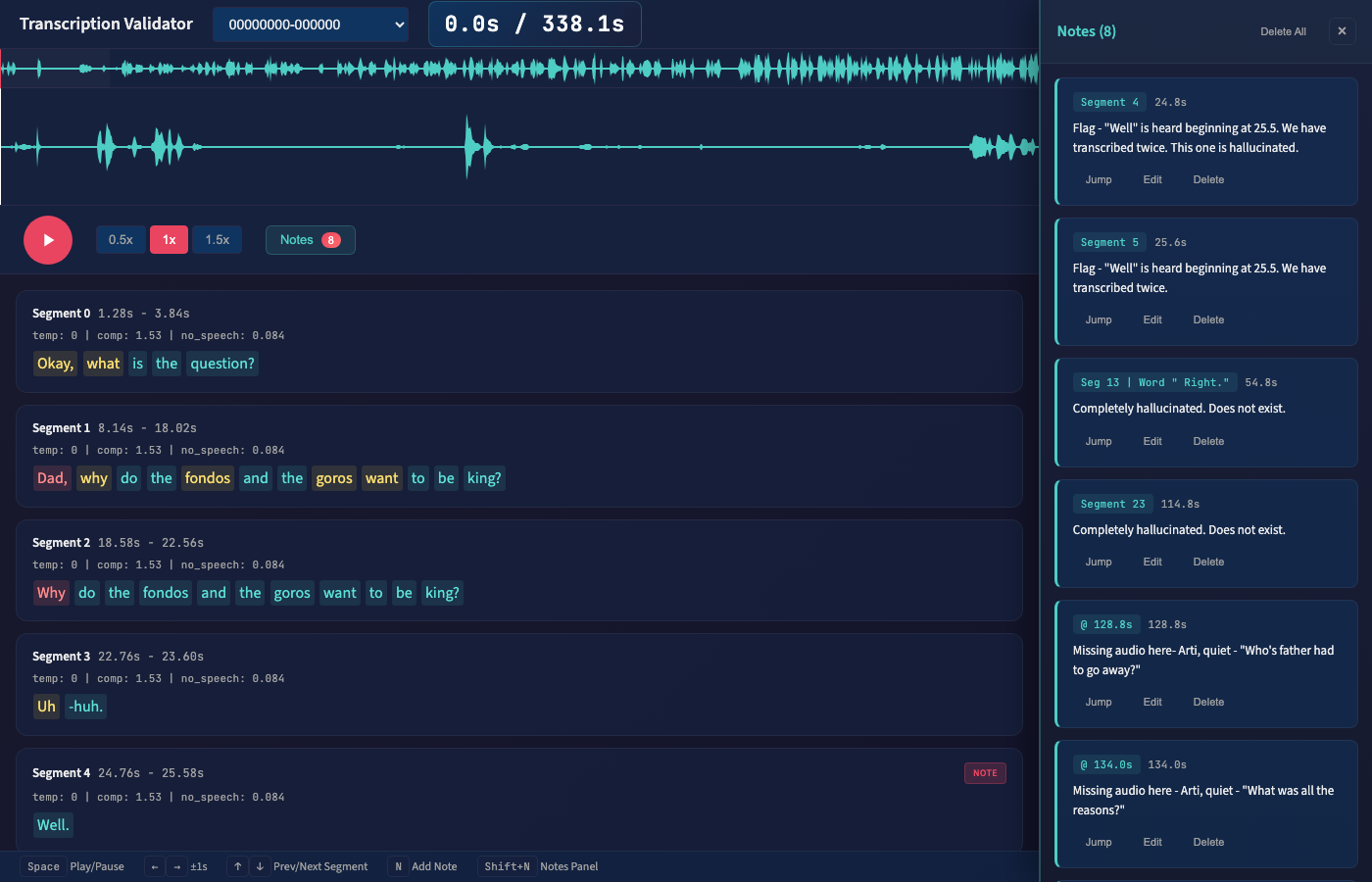
Validation Player, Take Two
I scrapped the existing validation player and rebuilt it.
The first version tried to do everything: verify transcription accuracy AND speaker labels.
The new version focuses solely on: what did Whisper hear? Waveform, word highlighting, playback controls, and more robust note-taking features. Diarization validation can come later, once I trust the transcription.
Process note: I built the first version by having Claude Code write specs and implementation together. For the rebuild, I developed the spec in Claude Chat first—thinking through the workflow, what I actually needed to see—then handed a clean spec to Claude Code for implementation. Better results. Separating "what should this do" from "how do I build it" helped me think more clearly about both.
Whisper Needs Context
Short clips produced different transcriptions than the full recording. Arti's opening question:
| Clip Length | Transcription |
|---|---|
| 38s – 210s | "Dad, why do the Fondos and Goros lose?" |
| Full (5min) | "Dad, why do the Fondos and Goros want to be king?" ✓ |
Whisper uses future context to disambiguate unclear audio. The full conversation — all the later discussion about Yudhishthir and Duryodhan wanting the throne — helps the model correctly interpret Arti's slightly unclear speech.
Implication: Process full recordings, don't chunk before transcription. For bedtime audio where a child's voice can be soft or unclear, the surrounding context is what makes accurate transcription possible.
Orphaned Phrases
Sometimes gaps in diarization lead to phrases with no assigned speaker label. How do I assign those mystery phrases?
First, I tried time-based rules. If the gap is under 0.5 seconds with the same speaker on both sides, assign the orphan to that speaker. This worked for most cases. But then I bumped into this:
| Speaker | Utterance |
|---|---|
| ME | Why do the Fondos and the Goros want to be king? |
| [UNKNOWN] | Uh-huh. |
| ME | Well, so the oldest brother... |
"Uh-huh" is Arti between my sentences. My timing rule assigns it to me. So I'm trying a different approach: LLM post-processing. Feed the transcript to a local model, let it use semantic context to assign the mystery phrases.
Validation Player
Designed a Flask + wavesurfer.js player for reviewing transcripts against audio. Click a word, hear the moment. Waveform visualization, word-level highlighting synced to playback, keyboard shortcuts for efficient review.
Learning: Spec iteration is valuable. Started with basic playback, ended with word-level highlighting and a notes system. Each addition came from thinking through the actual validation workflow.
Real-World Testing
Tested the pipeline on two actual bedtime recordings. Speaker separation worked well. Arti's
quiet voice captured in many places. [unintelligible] markers appeared where
speech faded out.
Sanskrit names: Whisper struggles as expected.
| Actual Name | What Whisper Heard |
|---|---|
| Yudhishthira | "Udister" |
| Pandavas | "Fondos", "Bondos", "Pondos" |
| Kauravas | "Goros", "Koros" |
| Dhritarashtra | "The Trasht" |
This confirms the name correction problem is real.
JSON Output & Schema
Built session persistence. The system now captures audio, processes it, and saves structured JSON with word-level timestamps. Schema includes placeholders for speaker names, story moments, and processing stats.
{
"word": "Pandavas",
"start": 3.28,
"end": 3.84,
"probability": 0.92
}Design principle: "Capture generously, build features sparingly." Word-level data enables future caption sync — audio plays, words highlight like Apple Music lyrics.
Hallucination Filtering
Deep dive into Whisper hallucination detection. Discovered word-level signals (probability, duration) weren't enough — some hallucinated words have high confidence. Moved to segment-level signals.
Before: "...and they lived happily ever after. Thank you. Thank you. Thank you."
After: "...and they lived happily ever after. [unintelligible]"The solution: Two-layer filtering. Segment filter marks real-but-unclear
speech as [unintelligible]. Word filters delete fabricated content entirely.
"Honest transcripts, not clean transcripts."
Pipeline Refactor
Investigated remaining UNKNOWN speakers. Found a pattern: turn-starts that diarization missed. These fragments end exactly where the next utterance starts — same speech event, boundary missed.
Before: UNKNOWN: "So the—"
SPEAKER_00: "—oldest brother..."
After: SPEAKER_00: "So the oldest brother..."The fix: assign_leading_fragments — if an UNKNOWN ends within
0.5s of the next speaker's turn, assign it to them. Reduced unknowns from 75 to 1. Also
extracted pipeline.py as standalone orchestration module.
Alignment Pipeline
Built the alignment pipeline combining transcription (what was said) with diarization (who said it). Used word midpoints to assign speakers. Added merge logic for UNKNOWN segments sandwiched between same speaker.
SPEAKER_01: Dad, why do the Fondos and the Goros want to be king?
SPEAKER_00: The oldest brother of the Goros, his name was, do you remember?
SPEAKER_01: Durioden.Result: Reduced utterances from 159 to 23. Now reads as actual conversation. Arti's question, properly attributed.
Child Speech Discovery
Compared Whisper model sizes. The tiny model heard nothing during Arti's question — ten seconds of silence. The large model captured all 12 words: "Dad, why do the Fondos and the Goros want to be king?"
| Model | Arti's Question (7-18s) |
|---|---|
| tiny | [silence — nothing transcribed] |
| large | 12 words captured |
The stakes: If transcription can't hear Arti's voice, we lose half the conversation — the half that matters most for understanding how she engages with the stories.
Project Start
First transcription attempt on a 5.6-minute Mahabharata storytelling session. Set up project structure, virtual environment, and testing framework. Whisper phonetically guesses unfamiliar names: "Yudhishthira" → "you this there."
Why backend first: If I can't process audio into useful transcripts, nothing else matters. Device and UI are delivery mechanisms. Backend is the engine.