Tell Me A Story
A local-only system for capturing improvised bedtime stories.
View on GitHub → (opens in new tab)Origin
My daughter, Arti, shouts "Tell me a story!" 1,000 times a day at me. Then at bedtime, I'm commanded to make up three more before she'll go to sleep. Folks, it's the end of the night. My brain's melted. I love my four-year-old but telling "one more story" feels like a type of tiny torture.
Still, when it's done, I'm always glad we share this ritual. And sometimes, I'm impressed by what we create together.
Pappy, the boy who looks like whatever food he wants to eat, usually a quesadilla. Too good, Arti! A perfectly executed Hero's Journey arc about a talking fork. Who knew it could be done?
Those bedtime stories are told and gone. I decided I wanted to keep them.
Why and for what, I'm not sure yet. One side of my brain complains, "Do we really have to digitize everything?" But a little voice insists, "Build the thing. Do it your way. Keep these stories. See what comes next when we get there." Ok...
The System
Right now, capture is voice memos on a phone. It works, but a phone doesn't belong in that calm, quiet bedtime space.
When I lay my head down on Arti's silly Elmo chair, I want to keep it dark and calm. The plan is an ESP32 device (a tiny, cheap microcontroller common in smart-home gadgets) — screenless, dark-operable, tap once and it just works.
Local ML models turn recordings into speaker-labeled transcripts.
Everything runs on-device for family privacy.
Currently running on Apple Silicon. Next phase is a Jetson Orin Nano (a small AI computer that can run models continuously without a laptop in the loop).
There's a Session Reviewer tool for validating transcripts against audio.
For the real UI... I want to be able to SEE the stories. What that means exactly, I'll discover over time.
The Pipeline
Messy audio in, structured transcript out. Local processing.
Intake
Scan for new audio, set up session
Transcribe
Speech to text with word-level timestamps
Diarize
Identify who is speaking and when
Enrich
Attach speakers to words, mark gaps
Normalize
Fix mishearings, standardize names
Identify
Match speakers to known voices
The test recordings are of me telling Arti stories from the Mahabharata, recalling the ancient Indian epic I loved as a kid. It's crammed with Sanskrit names that make speech recognition systems sweat. Let's see what the models make of the Pandavas and Kauravas.
Whisper runs locally on Apple Silicon. It produces segments with word-level timestamps, which is what makes speaker alignment possible later. It handles Dad fine. But it doesn't know Sanskrit, and a four-year-old's pronunciation doesn't help.
Pyannote listens to the audio and maps out who is speaking when.
No words — just stretches of audio labeled by voice
Each word's timestamp lands it inside a speaker block — that's how it gets labeled. Pyannote doesn't know names, just SPEAKER_00 and SPEAKER_01. Real names come later, once the pipeline matches voiceprints to known speakers.
Sometimes pyannote heard a voice
but Whisper couldn't decode the words, especially when Arti is getting sleepy and her
voice drops to a murmur. The pipeline marks these moments
[unintelligible] rather than pretending nobody spoke.
Two passes, one goal: correct the names. The LLM sees the full transcript and catches wild phonetic misses — "fondos" only maps to "Pandavas" if the model can see the surrounding conversation. The dictionary then standardizes transliteration variants: "Duryodhan" and "Duryodhana" are both real spellings, but only one is canonical.
The pipeline builds a voiceprint — a compact fingerprint of how each speaker sounds. It compares that fingerprint against known profiles. High-confidence matches are assigned automatically; the system learns Dad's voice from Arti's without being told every time.
When the pipeline encounters a voice it hasn't heard before, or isn't confident about, a dedicated speaker review page lets a human step in — confirm a match, create a new profile, or reassign. Those decisions persist across sessions and sharpen the voiceprint, so the system gets more confident over time.
Session Reviewer
The pipeline produces a transcript. But how do I know any of it is right? I built a tool to find out — play back audio against the transcript word-by-word, catch hallucinations, leave notes on anything suspicious.
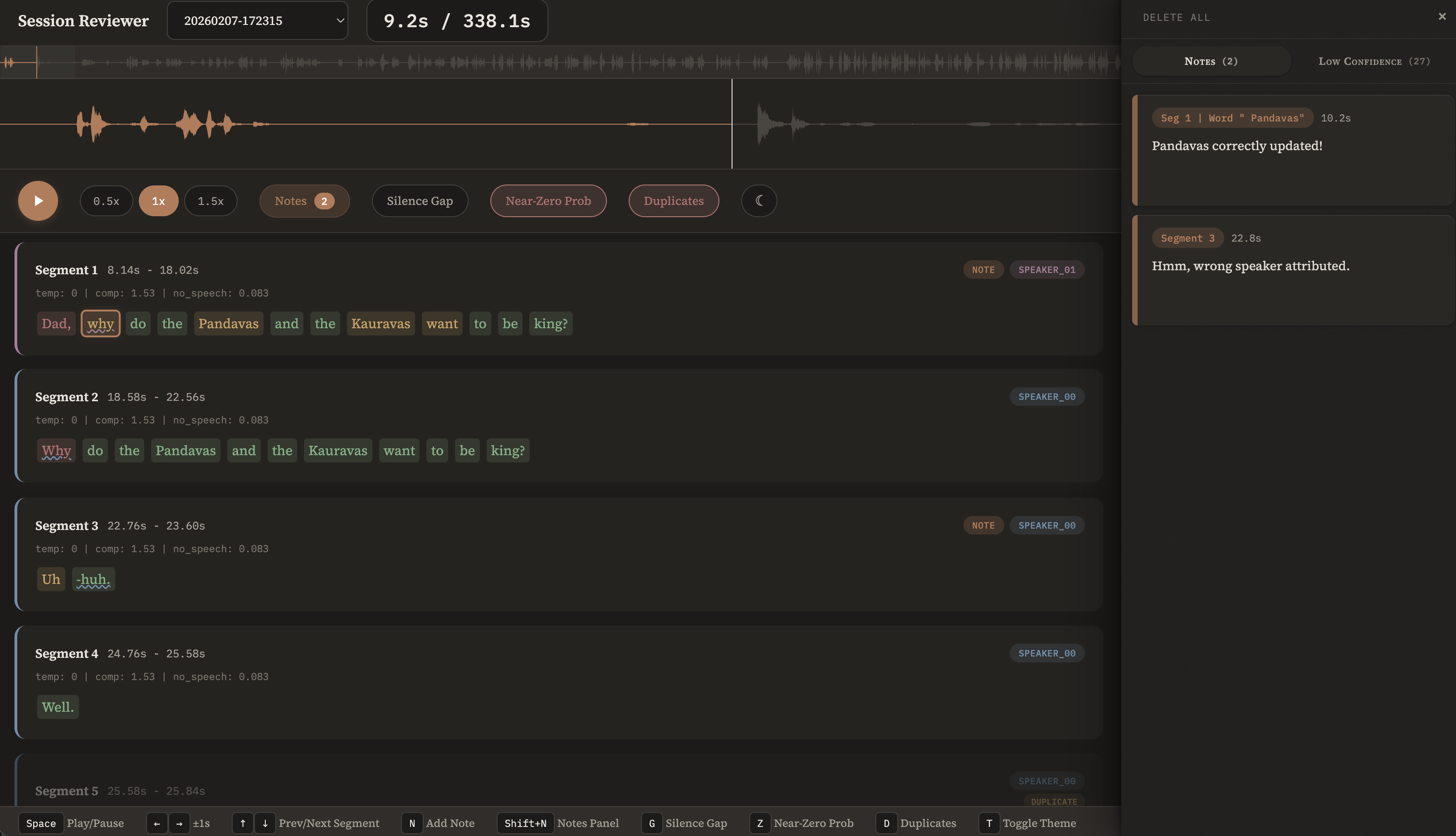 Click to enlarge
Click to enlarge
Hallucination Marking
Write confidence scores into the transcript from diarization coverage and word probability.
Session Classification
Break sessions into Stories, Conversations, Moments, and Other.
Story Element Extraction
Pull characters, events, and relationships from finished transcripts.
Fabricated speech
Whisper sometimes invents words during silence. Two independent systems disagree — that's the signal.
Diarization: no speaker detected, coverage 0.0
→ Flagged as hallucination
"Well." — probability 0.133, fabricated
→ Two consecutive identical words. One real, one not.
Inaudible child speech
Diarization detects Arti's voice at three points where Whisper produces nothing. The pipeline marks them honestly rather than dropping them.
Whisper: [no words produced]
→ Marked [unintelligible]
Model size is existential
Whisper's tiny model produces absolute silence where Arti speaks. The large model recovers her voice. This isn't an optimization — it's whether we capture half the conversation.
large: "Dad, why do the fondos and the goros want to be king?"
AI & Kids
Once I have transcribed stories, the generative AI applications seem easy and obvious. Extract recurring themes and characters using a sprinkle of local model intelligence? (Seems fine) Generate Nano Banana illustrations of characters in the style of famed Pixar illustrator, Sanjay Patel? (um.. not cool) Build an Eleven Labs powered penguin companion stuffy that tells stories with a voice that sounds exactly like Daddy? (OH GOD. WHAT HAVE I DONE)
Models were trained on creatives' work without permission or money, but the tech is here. It's not disappearing. Our kids will grow up with it. What should its place be in their lives? How do I approach building on such a fraught foundation? (Meanwhile, Choksi, you use AI for coding every day... what about that IP? Hypocrite!)
What does it do to a kid when their thoughts skip straight to a generated image? Isn't the whole point to have those ideas live in your head, and then if you decide to put in the effort, pick up a crayon and be delighted with what your hands can make? What happens when a four-year-old forms a relationship with something that talks back to her whenever she wants, optimized to build attachment, before her brain is fully cooked?
So where do I go once the audio → transcripts system is built? Not sure. I know the point isn't to outsource storytelling, creativity, or imagination to machines. It's to understand our voices as storytellers. And have fun.
I do believe this project will help me clarify my own red lines about AI/technology and kids. As I work on this, I'm talking to child development experts, artists, and writers in my children's media, animation, writing, and edTech networks to help sharpen my thinking.
Go Deeper
- "AI Is Breaking Education" — Your Undivided Attention with Rebecca Winthrop
- "AI in the Toy Box" — Common Sense Media (2026)
- "The Rise of AI Companions" — EdTech Insiders with Dr. Sonia Tiwari
- "Beyond the Engagement Trap: A New Design Architecture for Children & AI" — Michael Preston, Joan Ganz Cooney Center
Guiding Principles
Immediate Connection
Removing friction brings creative choices you could not have imagined before.
Ideas start out tiny, weak and fragile. — Victor
Hard Fun
Harness the passion of the learner to the hard work needed to master difficult material.
I have no doubt that this kid called the work fun because it was hard rather than in spite of being hard. — Papert
Calm Technology
Technology can live on the periphery, there when you need it, and otherwise invisible.
If computers are everywhere they better stay out of the way. — Weiser
The Arti Test
I only work on things for kids that I'd give my child.
Daaaaad, tell me a story whiiiiile I'm on the potty. — Arti
Learning
Part of why I am excited about this project: I get to learn things I actually want to learn.
- AI-assisted development (Claude Code)
- Audio ML pipelines (Whisper, pyannote)
- IoT capture devices (ESP32)
- Edge ML deployment (Jetson, CUDA)
- Local-first architecture
When I realized this bedtime story project gave me a reason to explore NVIDIA's CUDA/Jetson stack, I was unreasonably happy. Robot-brain tech! Positronic! That's exciting. And I do want to have a voice in the rooms where these things that will interact with us — our families, our kids — get built.